Longer term
Soon enough, the Schema for the front-end will look like this:
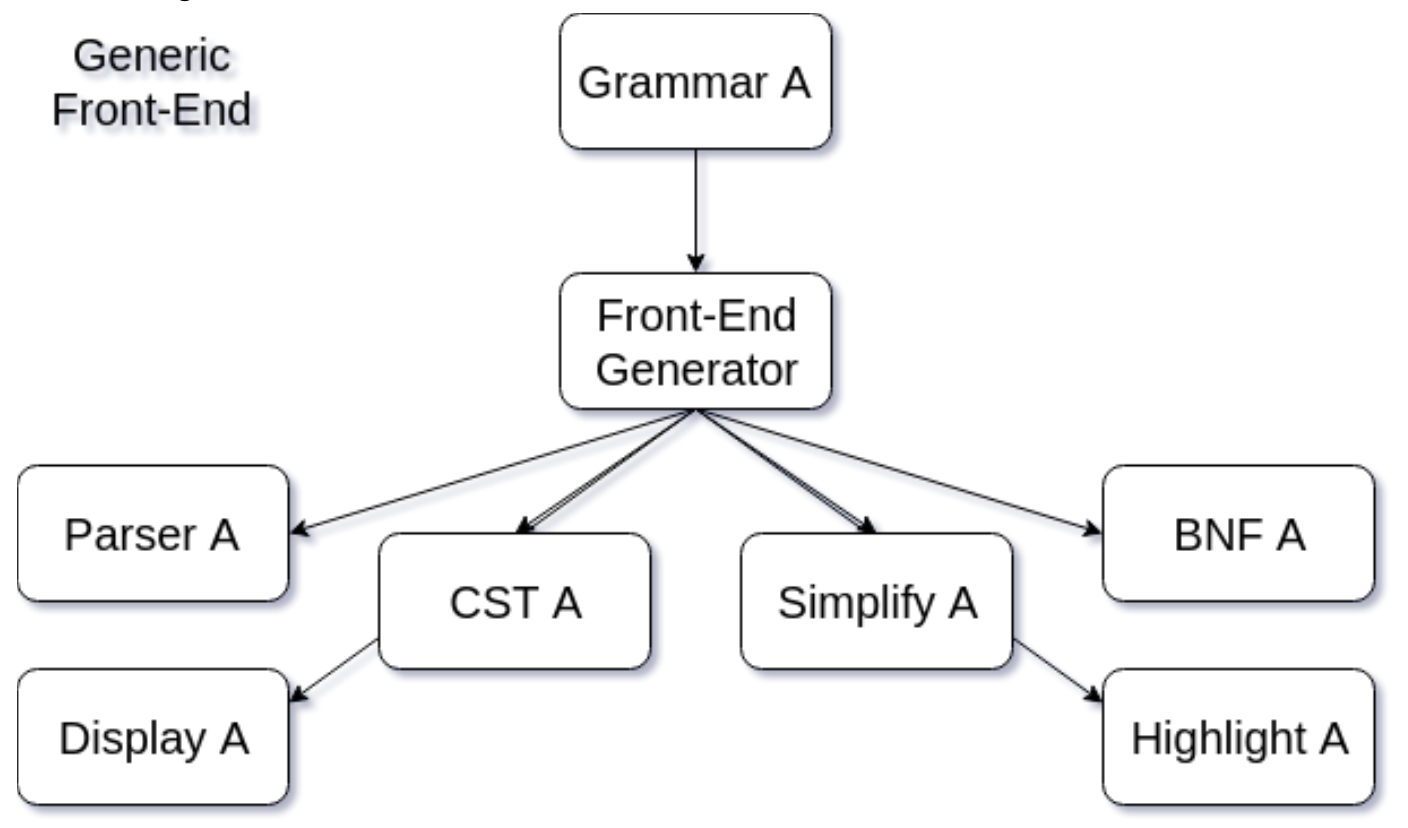
Basically, as we support more syntaxes (up to half a dozen), we’ll have a bigger need for a unified representation and generation of the helpers around it. For instance: Parsers. So far, parsers are generated by LR grammars. LR grammars have a steep learning curve, regularly making not worth it for someone to learn the whole formalism to extend a given grammar with a few cases. Generating those LR Grammars would thus save a lot of time. Displayers. The idea is that if you can parse and display code in a given syntax, it becomes much easier to have a translator between each syntax. So that not only it becomes possible for users to write code in their favourite syntax, but also to only read code in their favourite syntax. BNFs. BNF grammars are a common formalism to represent grammars. They are understood by many tools, and are an easy way to document a given syntax.
Super Type System
Soon enough, the Schema for the middle-end will look like this:
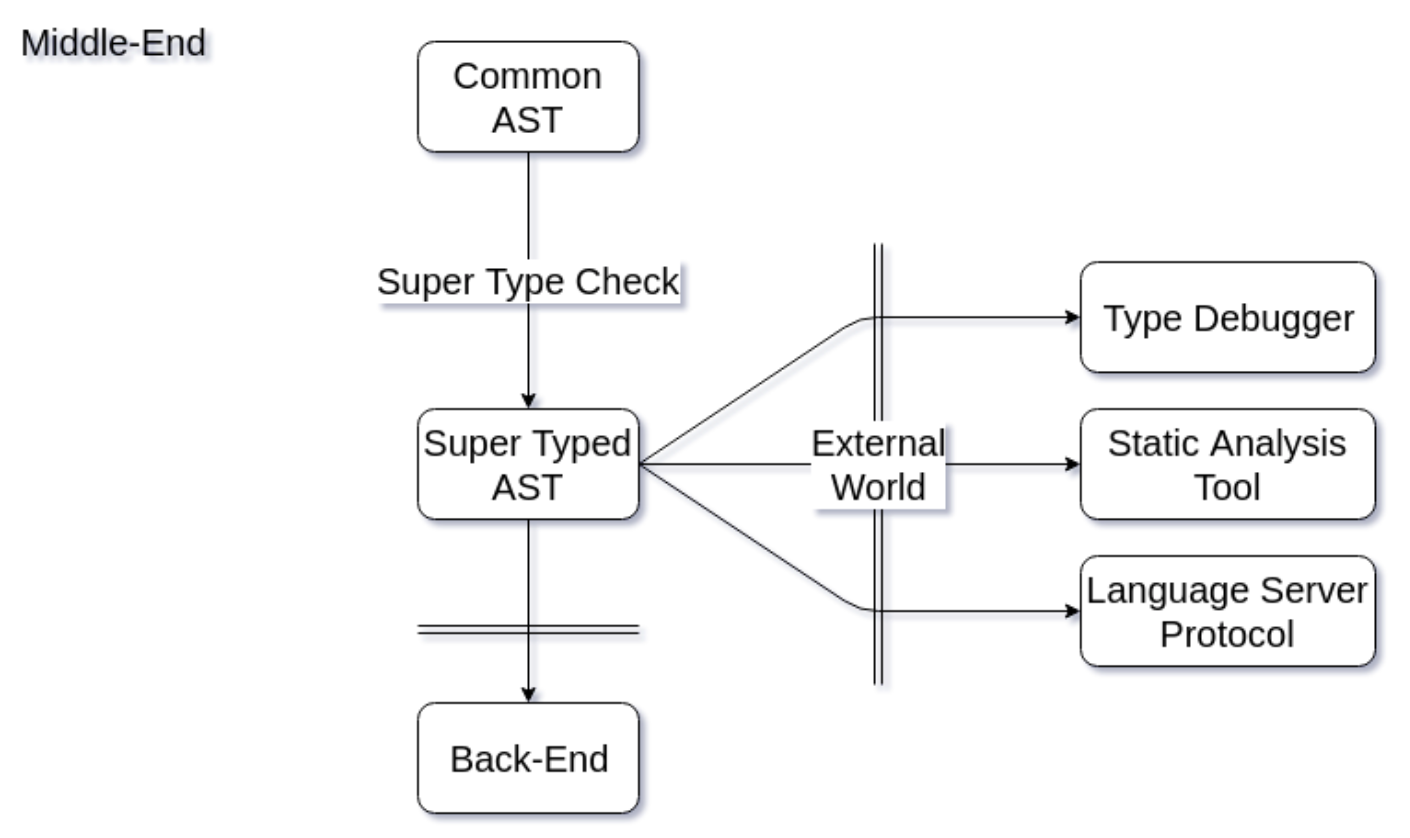 Basically, this schema shows that the Back-End will stop being the main consumer of the Typed AST, and the External World will in its stead.
As such, annotating the AST with quality information, documenting it and exposing the libraries that produced the information in the first place will be paramount.
The imagined type-system so far is a mixture of MLF, extensible data-types and Algebraic Effects.
Basically, this schema shows that the Back-End will stop being the main consumer of the Typed AST, and the External World will in its stead.
As such, annotating the AST with quality information, documenting it and exposing the libraries that produced the information in the first place will be paramount.
The imagined type-system so far is a mixture of MLF, extensible data-types and Algebraic Effects.